I finally found some time to overhaul the OpenGL ES hardware database. I admittedly neglected my OpenGL databases in recent years (mainly due to Vulkan ® and a severe lack of spare time), and especially the OpenGL ES one was in dire need of an overhaul and a cleanup. So I spent a few days fixing lots of problems (both technical and data-related) as well as getting it (mostly) on par with the Vulkan hardware database and the changes are now live.
In general the database should now run much faster and contain better data. If you notice anything (errors, bugs, missing data) drop me a line.
So here is a small run-down of the stuff that has been changed and fixed.
Server-side processing
Up until now each time the report listing page was loaded all 2k+ reports were fetched and delivered as a single table to the client where it then was processed via JS (pagination, filtering, sorting). This resulted in long page loads and all the data table functionality (like filtering) would only become available after the client had processed the whole table.
Even on a fast connection with a fast PC this took 5 or seconds in which you couldn’t do anything with the data:

So just like the Vulkan database, with server-side processing the client will now only fetch the actually visible number of records, moving load from the client to the server, resulting in dramatically lower page load times:

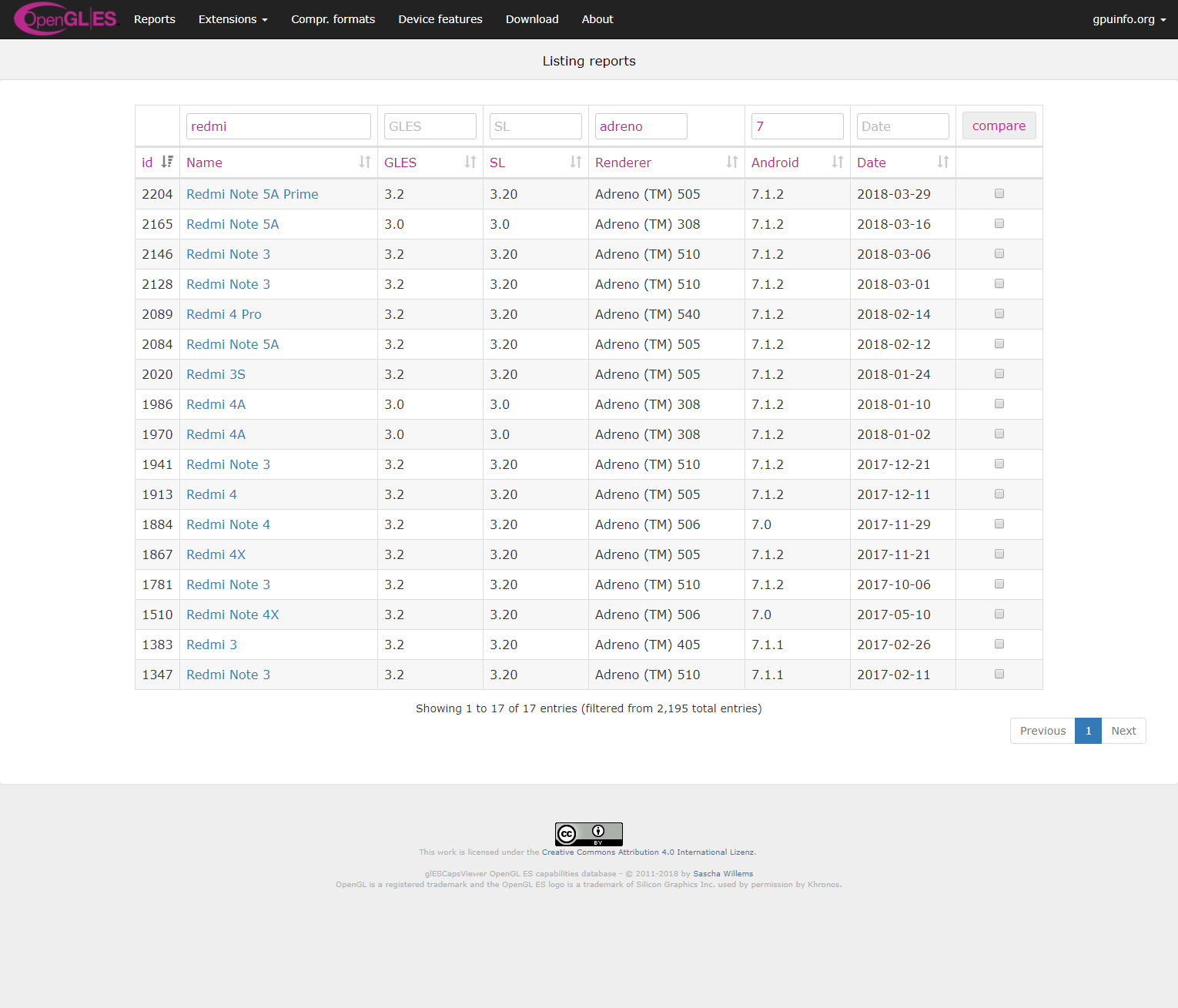
Filtering and sorting is now done server-side too, and the database makes use if this by implementing advanced and combined filtering, giving you more possibilities for restricting visible data:
Updated visual style
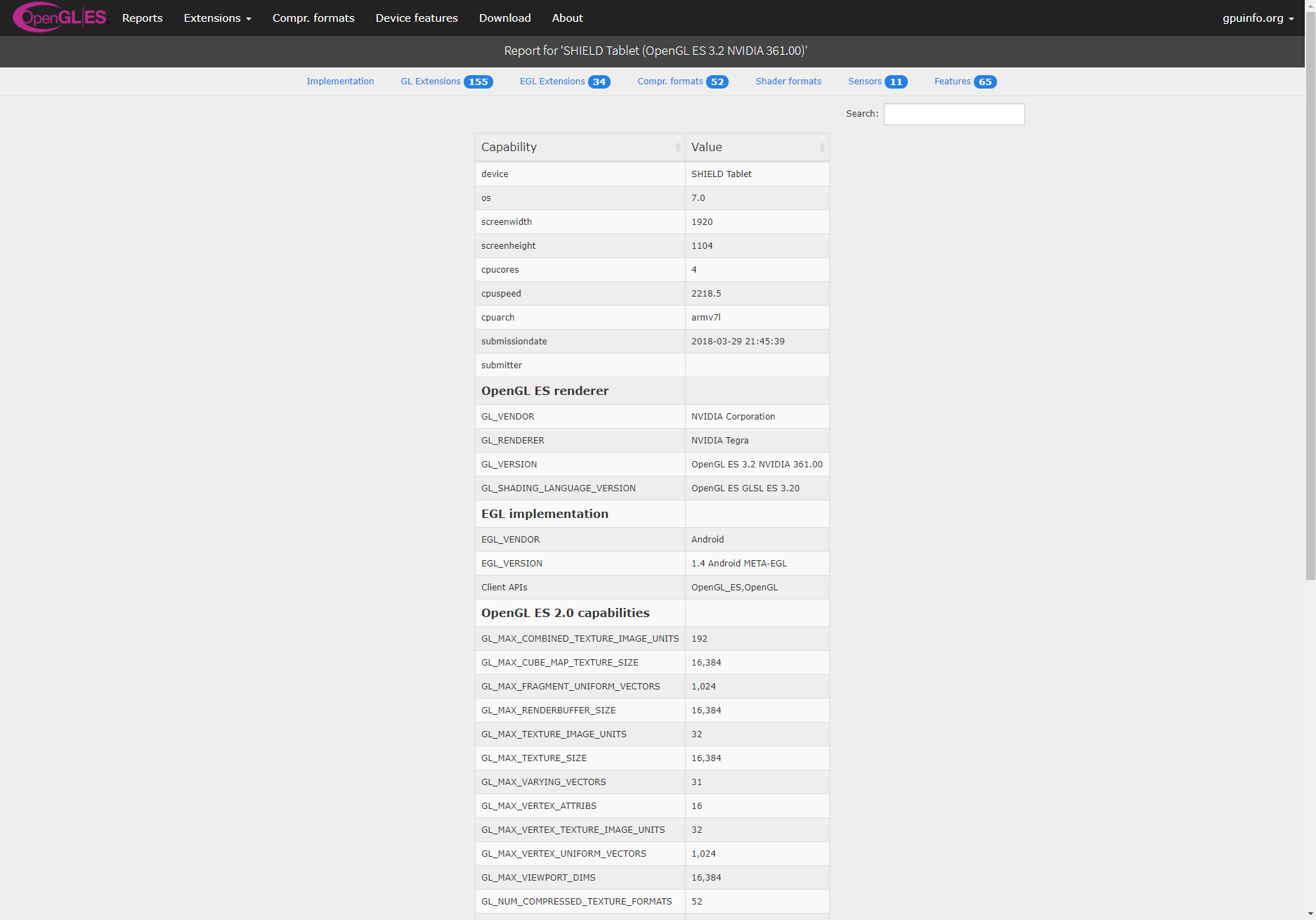
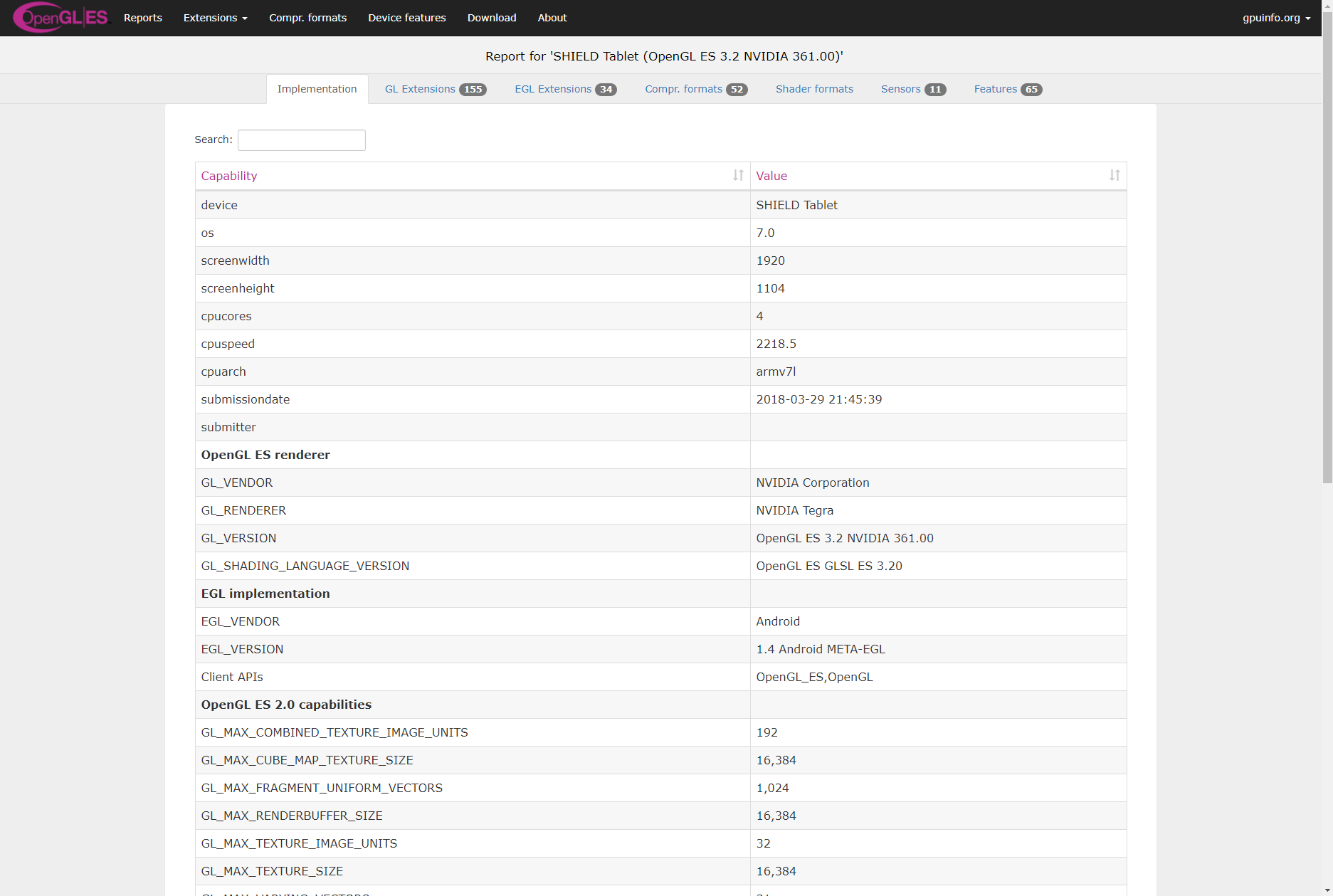
The OpenGL ES hardware database now uses the same visual style as the Vulkan one in order to unify styles across all of my databases (the OpenGL one will be updated too). A few of the listings and esp. the report display page looked pretty ugly (small fonts, controls all over the place), so they all now use a more modern, sleek and easier to look at (and read) style.
Report list (left: before, right: after):


Report display (left: before, right: after):
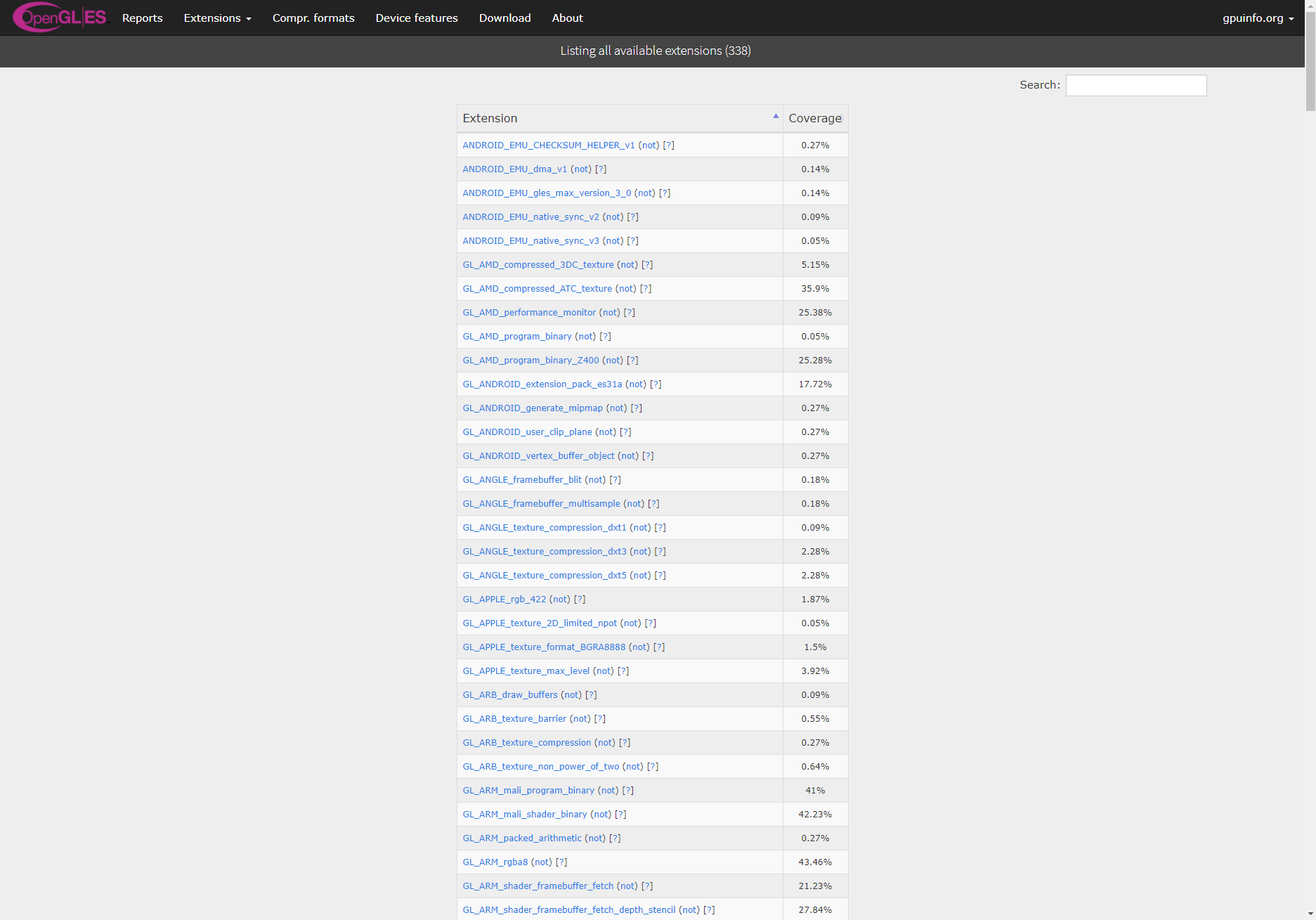
Extension list (left: before, right: after):
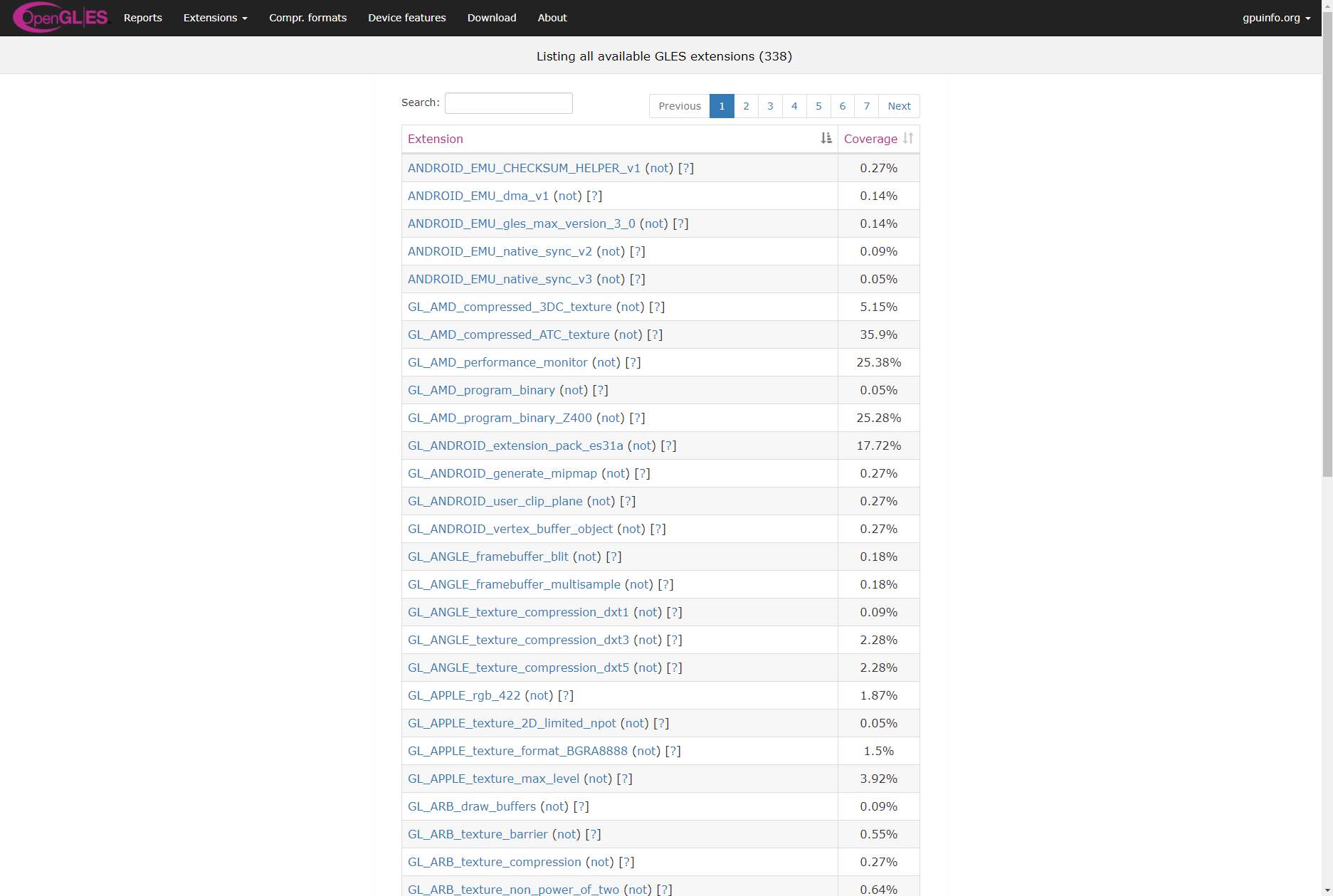
Renamed URLs
The old urls always contained a “gles_” prefix, due to the fact that the OpenGL ES and OpenGL databases initially ran from the same domain and folder on the server. As such I have changed all urls, removing the “gles_” prefix and getting more in line with the Vulkan database.
Note: The old urls will still be available for some time before I’ll change the server rules to rewrite them to the new ones.
Database changes
When I created the database design for the OpenGL hardware database back in 2013 I wasn’t that much experienced with web development and SQL databases in general having just started a developer job in a company where SQL was widely used, so compared to the Vulkan database, the design has it’s flaws, and only updating the visuals wouldn’t really make it that much better.
Optimized statements and indices
Now that the database is filled with lots of data (the largest table already contains more than 100k rows) I noticed that a few of the statements took pretty long. But thanks to MySQL’s explain feature I found a few bottlenecks, added some required indices and reworked a few of the views that are used to aggregate data. This means that the listing pages (extensions, compressed formats, etc.) should now load much faster.
Fixing compressed formats
This one took almost a full day due to multiple problems. Biggest problem was a missing unique rule on one of the columns for the formats pivot table. Uploading reports was supposed to fill this table only if a report with an unknown format was uploaded (using insert into with ignore) but due to the missing unique flag on that column each upload added it’s own set of compressed formats to that pivot table, resulting in more than 55k rows (which was also the reason why the compressed format listing page didn’t work anymore).
Fixing such an oversight in SQL isn’t easy once the damage has been done because I didn’t want to break any existing reports, so after a few hours of cautiously running some complex statements against the database I was able to fix the pivot table, the table design (making the column unique) and not break any reports.
After that was done I also went on and fixed almost 100 doubled formats from an older version of the glesCapsViewer application. The database actually stores format names instead of their enums (which in hindsight was a huge mistake) and older version uploaded formats without the GL_ prefix, resulting in single formats getting two entries (e.g. COMPRESSED_RGB8_ETC2 and GL_COMPRESSED_RGB8_ETC2). Fixing this wasn’t trivial either, but now the compressed format listing page is loading up again (and pretty fast to say) and only contains valid values.
General data cleanup
I also noticed that a few uploaded reports contained odd data in odd places. E.g. one report had an extension called “GL_nary” which sounded like bogus and also had all compressed formats uploaded as extensions instead of formats, adding them to the global extension listing. I removed these values and will check if there are any more reports that seem bogus to keep the database clean.